Ring Buffer Series Part 4 — Iterators: Walking the Ring
 In Part 3 we expanded on the original buffer and it now supports any type and any size. Our RingBuffer almost behaves like any of the
In Part 3 we expanded on the original buffer and it now supports any type and any size. Our RingBuffer almost behaves like any of the STL types, such as std::vector and I say almost. Consider the following code:
int main()
{
RingBuffer<int, 10> my_buffer;
for (int i = 0; i < 10; ++i)
{
my_buffer.push_back(i);
}
for (auto x : my_buffer) // This line produces an error.
{
std::cout << x << ' ';
}
}
This code should work, but if we actually try to run it we will get a compiler error.
error: 'begin' was not declared in this scope
So, what’s wrong? Recall in a previous post we used code similar to the following.
int main()
{
std::vector<double> numbers{1,2,3,4,5,6,7,8,9,10};
// We use std::max_element
auto max_pos{std::max_element(numbers.begin(), numbers.end())};
double max_value{*max_pos};
// We use std::min_element
auto min_pos{std::min_element(numbers.begin(), numbers.end())};
double min_value{*min_pos};
}
Take a look at how max_pos and min_pos are calculated. You will notice that use of two functions. .begin() and .end(). Now, the compiler error starts to make sense, our template class does not have a begin() function of its own and even if it had one, there is no .end() function either. This means that there is still work to do!
The Range-Based for Loop
The range-based for loop was introduced in C++ 11. Its goal is to simplify iterating over collections.
When we write something like for(auto i : collection), the compiler rewrites it into a traditional for loop that uses iterators to navigate the range. The produced code would looks something like this.
{
auto __begin = collection.begin();
auto __end = collection.end();
for(; __begin != __end; ++__begin){
i = *__begin;
//Statement
}
}
There are 5 requirements for us to be able to implement this functionality in our RingBuffer class.
.begin(): The compiler first looks for a member function (or a global function via ADL) that returns an iterator pointing to the first element..end(): It similarly requires a function returning a past-the-end sentinel, which marks the position immediately after the last valid element.operator!=: The loop uses this to compare the current position (__begin) against the sentinel (__end) to determine if the iteration should continue.operator++: The prefix increment operator is required to advance the iterator to the next logical element in the sequence.operator*: The dereference operator must be implemented so the loop can access and assign the value at the current position to your loop variable.
I know this is a lot, but don’t worry, we will expand on these. Let’s begin by defining one word I have been using quite lot lately; iterator what is that?
What is an Iterator?
An iterator is an object that acts as a generic abstraction for accessing and traversing a container. Iterators are what allow one algorithm to work in different kinds of containers likes std::vector or std::list without having to know the way they are implemented, for example an algorithm can sum values in a sequence whether those values are stored in a std::vector or std::list.
A sequence is typically defined by a pair of iterators: begin() which points to the first element and end() which points to “past the end” which is one position after the last element.
Now that we know what an iterator is, let’s start implementing one for our RingBuffer.
Naive Approach
Our iterator implementation jumps straight into modular arithmetic with the % operator, but why do we need it? Consider what would happen if we follow the most intuitive approach:
//Naive approach (DO NOT USE THIS)
T& operator*() const{
return rb_->buffer_[index_]; //index_ IS the array position
}
iterator& operator++(){
++index_; //Just move to the next slot
return *this;
}
If we push 5 elements into RingBuffer<int, 8>, head_ is at 0 and tail_ is at 5. The naive iterator would start at index 0, walk to 1 to 2 to 3 to 4 and everything works perfectly.
Now, consider what happens when the buffer wraps. We push 10 elements into the same buffer of size 8. The first two elements have been overwritten, head_ is now at index 2 and tail_ is at index 2 (they have lapped). The valid elements sit at indices 2,3,4,5,6,7,0,1 in that logical order.
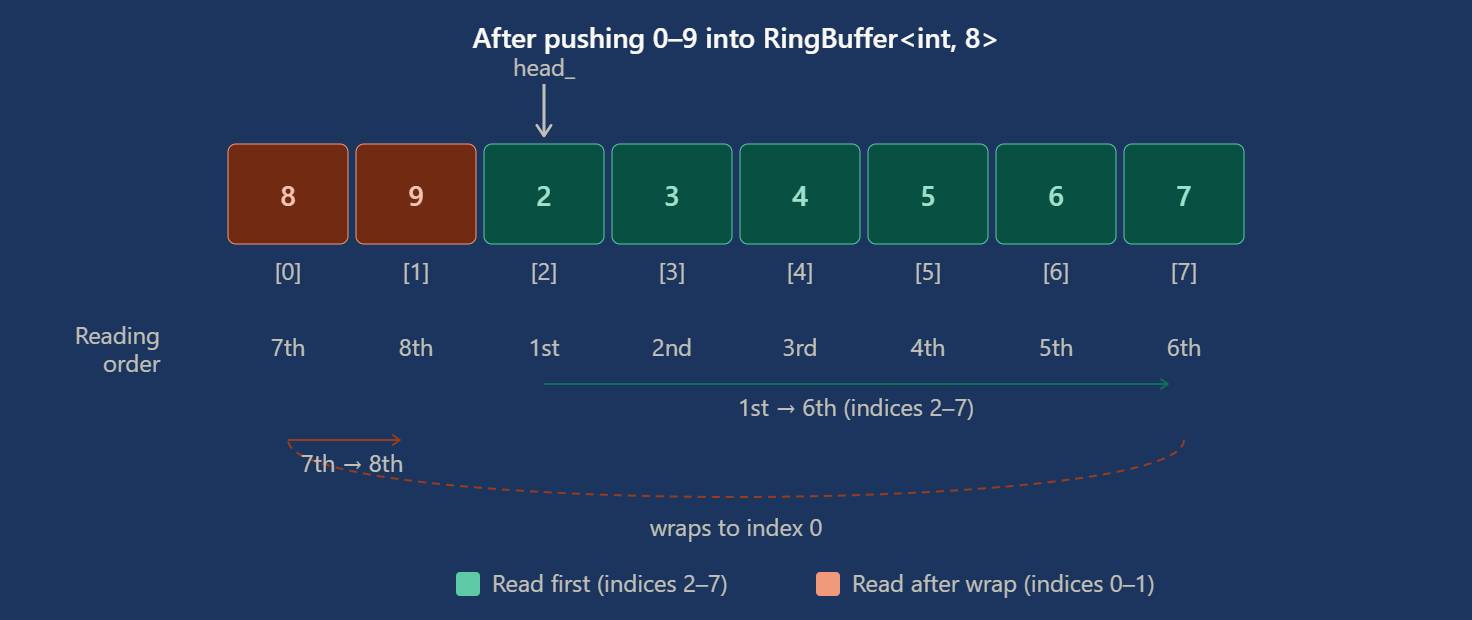 Our naive iterator starts at index 2 (
Our naive iterator starts at index 2 (head_) and increments 2,3,4,5,6,7..8, but look index 8 does NOT exist which means we have walked off the end of the array.
This is the same problem we solved with our print_buffer() with the if check.
index++;
if(index >= N){
index = 0;
}
For the iterator, we use modular arithmetic to achieve the same wraparound in a single expression. Instead of storing a raw array index, we store a logical offset, that is, how many steps we have taken from head_. The actual array position is always (head_ + offset) % N:
| Logical offset | Calculation (head_=2, N=8) | Physical index |
|---|---|---|
| 0 | (2 + 0) % 8 | 2 |
| 1 | (2 + 1) % 8 | 3 |
| 5 | (2 + 5) % 8 | 7 |
| 6 | (2 + 6) % 8 | 0 ← wrapped! |
| 7 | (2 + 7) % 8 | 1 |
The modulo operator handles the wrap automatically. No if check needed. With that understanding, let’s look at the actual implementation.
Nested Iterator Implementation
A way to implement the iterator is by declaring it as a nested class inside the RingBuffer. An advantage to this approach is that is that it allows to maintain a clean and standard interface. Our ring buffer iterator needs to behave in such a way that the iterator can navigate from head_ to tail_ while handling the array’s wrap around. Consider the following:
#ifndef RINGBUFFER_H
#define RINGBUFFER_H
#include <iostream>
template <typename T, std::size_t N>
class RingBuffer
{
public:
class iterator{
public:
T& operator*() const{
return rb_->buffer_[(rb_->head_ + index_) % N];
}
iterator& operator++(){
++index_; //Move to the next logical element
return *this;
}
bool operator!=(const iterator& other) const{
return index_ != other.index_; //Compare logical positions
}
private:
friend class RingBuffer; //Allow RingBuffer to construct iterators
iterator(RingBuffer* rb, std::size_t index) : rb_{rb}, index_{index}{}
RingBuffer* rb_; //Pointer to the parent container
std::size_t index_; //Logical offset from the head
};
//Container requirements to yield iterators
iterator begin() {return iterator(this, 0);} //First element
iterator end() {return iterator(this, count_);} //Past-the-end sentinel
RingBuffer(); //Constructor
~RingBuffer(); //Destructor
void print_buffer() const; //Outputs the buffers contents to the screen
void push_back(const T& new_element); //Adds a new element into the buffer
void pop_front(); //Deletes the oldest element from the buffer
bool empty() const; //Is the buffer empty
bool full() const; //Is the buffer full
const T& front() const; //Retrieves the oldest element
std::size_t size() const; //Retrieves the number of elements in the buffer
private:
T buffer_[N]; //Notice that now it take N and not 8.
std::size_t head_; //Index of oldest element (read position)
std::size_t tail_; //Index of next write position
std::size_t count_; //Total number of elements in the buffer
};
//Now, everywhere where we had the hardcoded 8 can be updated to use N
template <typename T, std::size_t N>
RingBuffer<T, N>::RingBuffer() : buffer_{}, head_{}, tail_{}, count_{} {}
template <typename T, std::size_t N>
RingBuffer<T, N>::~RingBuffer() {}
template <typename T, std::size_t N>
void RingBuffer<T, N>::print_buffer() const
{
std::size_t index{ head_ };
for (std::size_t i = 0; i < count_; i++) {
std::cout << buffer_[index] << ' ';
index++;
if (index >= N) {
index = 0;
}
}
std::cout << '\n';
}
template <typename T, std::size_t N>
void RingBuffer<T, N>::push_back(const T& new_element)
{
if (count_ == N) {
//Buffer full - We are about to overwrite oldest element
head_++;
if (head_ >= N) {
head_ = 0;
}
}
else {
count_++;
}
buffer_[tail_] = new_element;
tail_++;
if (tail_ >= N) {
tail_ = 0;
}
}
template <typename T, std::size_t N>
void RingBuffer<T, N>::pop_front()
{
if (count_ == 0) {
// Buffer empty, nothing to remove
return;
}
head_++;
if (head_ >= N) {
head_ = 0;
}
count_--;
}
template <typename T, std::size_t N>
bool RingBuffer<T, N>::empty() const
{
return count_ == 0;
}
template <typename T, std::size_t N>
bool RingBuffer<T, N>::full() const
{
return count_ == N;
}
template <typename T, std::size_t N>
const T& RingBuffer<T, N>::front() const
{
assert(!empty());
return buffer_[head_];
}
template <typename T, std::size_t N>
std::size_t RingBuffer<T, N>::size() const
{
return count_;
}
#endif // RINGBUFFER_H
Operator Overload
There is a lot to unpack here, let’s go over it a little bit slower.
Inside the RingBuffer class we are creating an iterator class. Then we have three functions inside the iterator class, notice the operator keyword (operator*, operator++ and operator!=).
The operator keyword lets us define how standard C++ operators (+,==,[],*, and others) behave when used with our custom types. When we write *ptr on a raw pointer the compiler already knows what * means, but when we write *it on our own iterator class, the compiler has no idea what to do unless we tell it. That’s what operator* does, it teaches the compiler how to dereference our type. The same idea applies to ++ and !=. The compiler knows how to increment an int, but it doesn’t know how to advance our iterator to the next element in a ring buffer, that is our job to define.
Dereference: T& operator*()
Consider the following:
T& operator*() const{
return rb_->buffer_[(rb_->head_ + index_) % N];
}
The * allows the iterator access to the element at the iterator’s current position. The RingBuffer is a special case, so we had to define a special operation. We must provide logical to physical mapping, this means that the “first” element is not always at array index 0, it is at head_. To find the actual element, the code takes the logical index_ (0,1,2,3…), adds it to the physical head_ and applies the modulo operator (% N). This ensures that if the iteration “walks off” the end of the physical array, it wraps back around to the beginning correctly.
Prefix Increment: iterator& operator++()
iterator& operator++(){
++index_; //Move to the next logical element
return *this;
}
The ++ operator advances the iterator’s logical index_ by 1 (0 to 1 to 2 to 3…) and returns a reference to itself (*this) which avoids unnecessary copies required by the postfix it++.
Inequality: bool operator!=()
bool operator!=(const iterator& other) const{
return index_ != other.index_; //Compare logical positions
}
The range-based for loop uses this to determine when to stop. It compares the current iterator’s logical position with the “past the end” sentinel end(). In our buffer end() return an iterator with index_ equal to count_. This operator will terminate the loop when the iterator has processed every valid element in the buffer.
Inline Functions
Perhaps you noticed that the functions in the iterator class are defined inline inside the class. There are a few reasons why we do this.
First, it allows us to avoid overly verbose syntax that becomes overly repetitive and difficult to read. The iterator class is inside a class template, so if we were to define it outside of it the code would look like this:
template <typename T, std::size_t N>
typename RingBuffer<T, N>::iterator& RingBuffer<T, N>::iterator::operator++(){
//...Function Definition
}
This is a lot of boilerplate that does not give us any kind of benefits.
Second, any function defined directly within the class body is treated as we were using the inline keyword. In most cases this keyword gives an optimization hint to the compiler which will attempt to make the code more performant and performance is critical for an iterator because operator++ and operator* could be called millions of times inside loops.
Third, unlike regular classes, the compiler needs to “see” template class definitions at all times so it can instantiate those classes, as we learned in Part 3, template definitions must live in the header file anyway. so it is more practical to keep the definitions inside the class itself.
The Power of Friendship
I am sure you also noticed the following line in the iterator class.
friend class RingBuffer;
What happens when we create a class inside a class, the nested class has access to the elements of the class that encloses it. In this case our iterator class has access to everything in RingBuffer, however the same doesn’t work in reverse. RingBuffer has no access to the private elements of iterator. In our implementation, begin() and end() of the RingBuffer need to call a private iterator constructor. If we don’t use the power of friendship, then the compiler would block RingBuffer from creating the iterator objects it needs.
Seeing in Action
We are ready to take our buffer for a spin.
int main()
{
RingBuffer<int, 8> buffer;
// Push 10 values into a size-8 buffer, forcing a wrap
for (int i = 0; i < 10; ++i)
{
buffer.push_back(i);
}
// The moment we've been waiting for
std::cout << "Range-based for loop:\n";
for (auto x : buffer)
{
std::cout << x << ' ';
}
std::cout << '\n';
return 0;
}
And this is the output:
Range-based for loop:
2 3 4 5 6 7 8 9
Success! We now have a custom type that works like an STL type!
Let us ensure that this is the case by making another test.
int main()
{
RingBuffer<int, 8> buffer;
// Push 10 values into a size-8 buffer, forcing a wrap
for (int i = 0; i < 10; ++i)
{
buffer.push_back(i);
}
// The moment we've been waiting for
std::cout << "Range-based for loop:\n";
for (auto x : buffer)
{
std::cout << x << ' ';
}
std::cout << '\n';
// Remember these from the Input Basics series?
auto max_pos{ std::max_element(buffer.begin(), buffer.end()) };
auto min_pos{ std::min_element(buffer.begin(), buffer.end()) };
std::cout << "Max: " << *max_pos << '\n';
std::cout << "Min: " << *min_pos << '\n';
// std::find returns an iterator to the first match, or end() if not found
auto found{ std::find(buffer.begin(), buffer.end(), 7) };
if (found != buffer.end())
{
std::cout << "Found: " << *found << '\n';
}
return 0;
}
Uh? That is strange… it does not work anymore, it won’t even compile and depending on your system you will be met with cryptic errors similar to the following.
error C2794: 'value_type': is not a member of any direct or indirect base class of 'std::indirectly_readable_traits<RingBuffer<int,8>::iterator>'
What’s happening is that we have made our iterator class so that it will work with the range based loop which requires the three operators we defined (*,++,!=), unfortunately Standard Library algorithms like std::find and std::max_element need a bit of extra work.
The Missing Pieces
class iterator{
public:
// New: iterator traits for STL algorithm compatibility
using iterator_category = std::forward_iterator_tag;
using value_type = T;
using difference_type = std::ptrdiff_t;
using pointer = T*;
using reference = T&;
T& operator*() const{
return rb_->buffer_[(rb_->head_ + index_) % N];
}
iterator& operator++(){
++index_;
return *this;
}
bool operator!=(const iterator& other) const{
return index_ != other.index_;
}
// New: equality operator for STL algorithms
bool operator==(const iterator& other) const {
return index_ == other.index_;
}
private:
friend class RingBuffer;
iterator(RingBuffer* rb, std::size_t index) : rb_{rb}, index_{index}{}
RingBuffer* rb_;
std::size_t index_;
};
The rest of the RingBuffer remains unchanged.
The code now implements Iterator Traits and Equality Comparison, these are needed to bridge the gap between our RingBuffer and the Standard Template Library (STL) algorithms. Let me explain.
Iterator Traits
Iterator traits are a template structure std::iterator_traits that provides an interface for accessing metadata about an iterator, such as its category and the type of data it refers to. It decouples algorithms from containers and only needs to know an iterator’s capabilities and not which container it belongs to. The primary reason to use a traits class rather than the iterator directly is the raw pointer support. Raw pointer like int* don’t have member types or aliases, so algorithms cannot call T::value_type on them. std::iterator_traits provides a partial specialization for pointers, making sure they are recognized as random-access iterators with a valid value type.
Algorithms like std::find or std::min_element are generic and do not know the internal details of our RingBuffer, instead they use the helper std::iterator_traits template to inspect the iterator’s properties.
iterator_categorytells the algorithm what our iterator can do, we set it tostd::forward_iterator_tagto “promise” the algorithm that our iterator supports multi-pass traversal and at least the operations of an input iterator.value_typeidentifies the type of data being iterated (typeT), allowing algorithms to create temporary variables to store elements during processing (like when finding maximum)difference_typedefines the signed integer type used to represent the distance between two iteratorspointerandreferencealiases provide a standard way for algorithms to know how to point or to refer to underlying data.
The Equality Operator: bool operator==()
bool operator==(const iterator& other) const {
return index_ == other.index_;
}
A range based for loop only requires operator!=, but many STL algorithm use operator== to check if a specific value has been located or if two ranges are identical. Our implementation verifies that two iterators are at the exact same logical position (index_).
Without these additions our iterator works for simple loops, but fails with powerful tools like std::max_element because the compiler cannot determine the iterator’s capabilities or how to compare its positions.
Running it a Second Time
We will try the same code from before
int main()
{
RingBuffer<int, 8> buffer;
// Push 10 values into a size-8 buffer, forcing a wrap
for (int i = 0; i < 10; ++i)
{
buffer.push_back(i);
}
// The moment we've been waiting for
std::cout << "Range-based for loop:\n";
for (auto x : buffer)
{
std::cout << x << ' ';
}
std::cout << '\n';
// Remember these from the Input Basics series?
auto max_pos{ std::max_element(buffer.begin(), buffer.end()) };
auto min_pos{ std::min_element(buffer.begin(), buffer.end()) };
std::cout << "Max: " << *max_pos << '\n';
std::cout << "Min: " << *min_pos << '\n';
// std::find returns an iterator to the first match, or end() if not found
auto found{ std::find(buffer.begin(), buffer.end(), 7) };
if (found != buffer.end())
{
std::cout << "Found: " << *found << '\n';
}
return 0;
}
And the output is:
Range-based for loop:
2 3 4 5 6 7 8 9
Max: 9
Min: 2
Found: 7
Which means that it works, our iterator behaves almost exactly like an STL type!
What we have Accomplished
At the beginning we had a RingBuffer that couldn’t be used with range based for loops and now it can.
Our custom iterator handles the wraparound that makes the ring buffers tricky and with the additions of iterator traits, it works now with STL algorithms like std::find, std::max_element and std::min_element, the same one we used back in the input basics series, now this time we understand the mechanics behind them.
Now, look at the print_buffer(). It manually walks from head_ through the array with an if check for wrapping. Our iterator does the same thing, but in a way the entire standard library can use. This is the power of the iterator abstraction.
Next Steps
Our iterator works, but it has a limitation.
void print_contents(const RingBuffer<int, 8>& buf)
{
for(auto x : buf)
{
std::cout << x << ' ';
}
}
The compiler will not allow it. Our begin() and end() are not const qualified, which means they can’t be called on a const object. In the next post we will fix this by introducing const_iterator, an iterator that promises not to modify the elements it visits.